LightGBM
https://lightgbm.readthedocs.io/en/stable/
文献
- LightGBM: A Highly Efficient Gradient Boosting Decision Tree
- https://www.microsoft.com/en-us/research/publication/lightgbm-a-highly-efficient-gradient-boosting-decision-tree/
- 著者:Guolin Ke, Qi Meng, Thomas Finely, Taifeng Wang, Wei Chen, Weidong Ma, Qiwei Ye, Tie-Yan Liu
- 所属:Microsoft Research, Peking University, Microsoft Redmond
Install
macOS
brew install lightgbmpip install lightgbm
Features
https://lightgbm.readthedocs.io/en/latest/Features.html#features)
-
Histogram-based algorithms
- 連続変数値を離散的なビンの代表値に置き換える
(私:従って、作為的に荒くしたいなどの意図がなければ、自分でビニングする必要はない) - 訓練速度を向上させ、メモリ利用料を低減する
- 連続変数値を離散的なビンの代表値に置き換える
-
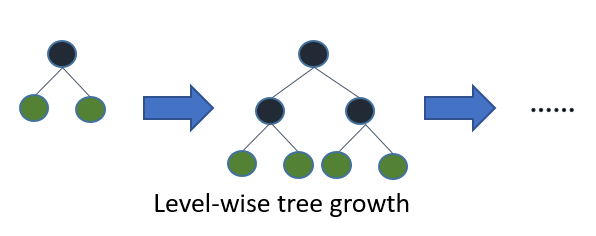
多くのアルゴリズムは level (depth)-wise に木が成長
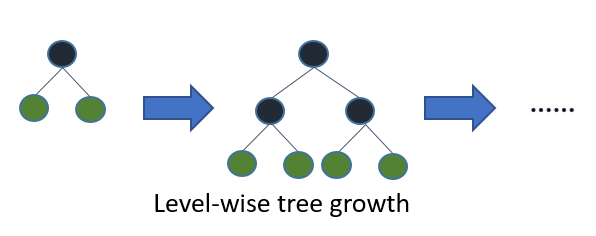
*オフィシャルサイトから引用 -
LightGBM は leaf-wise (best-first) に木が成長
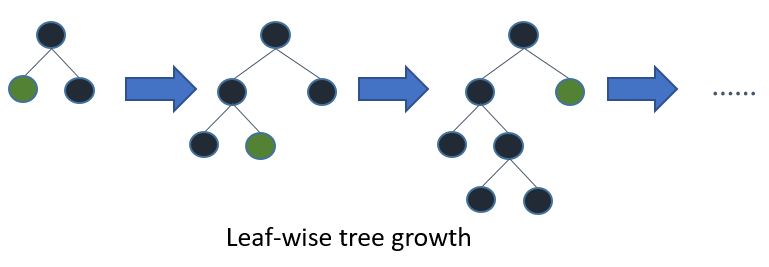
*オフィシャルサイトから引用
Parameters
https://lightgbm.readthedocs.io/en/latest/Features.html#features
Parameters Tuning
https://lightgbm.readthedocs.io/en/latest/Parameters-Tuning.html
Optuna for automated hyperparameter tuning
-
num_leaves
- Treeモデルの複雑さ(一つの木のノード数)を決定
- num_leaves = 2^(max_depth) は depth-wise tree と同じ葉の数になる
- 実際には、葉の数を固定した場合、 leaf-wise tree は depth-wise tree よりも深くなる
- したがって、深さを制限しないと過剰適合を起こす
- num_leaves を調節する際には、 2^(max_depth) とする
- 例えば、 max_depth=7 は depth-wise tree では高い精度を得ることが可能だが、num_leaves = 127 は過剰適合を起こす可能性がある。 70 や 80 などで、depth-wise より良い精度が期待できる
-
min_data_in_leaf
- ノードとして加えられるために最低限必要なデータ数
- leaf-wise tree で過剰適合を防ぐためのとても重要なパラメータ
- 訓練データのサンプルサイズとnum_leavesによる
-
max_depth(減らす)
- 木の深さを陽に制限したら、num_leaves も <= 2^max_depth 以下に陽に制限する
-
min_gain_to_split(増やす)
- 木に新たノードが追加される際、LightGBM はsplit point として、gain が最大になる点を選択する
- Gain はsplit pointを加えることによる訓練 lossの減少のこと
- LightGBM はデフォルトで min_gain_to_split を 0.0と設定(小さすぎる gain は存在しない)
- しかし実際上は、微小なgain はモデルの汎化誤差には有意に影響しないことが考えられる
Python API
https://lightgbm.readthedocs.io/en/latest/Python-API.html#data-structure-api
Data Structure API
- Dataset
- データセットクラス
- Booster
lgb.train(params, lgb_train, ...)の戻り値もこのクラスのインスタンス- fitメソッドはないが、追加学習させる
refit(data, label[, decay_rate, reference, ...])メソッドがある
- CVBooster
- Sequence
Training API
train(params, train_set[, num_boost_round, ...])- 訓練を実行
- 戻り値:訓練済みboosterオブジェクト
cv(params, train_set[, num_boost_round, ...])- クロスバリデーションを実行
- 戻り値:検証結果の辞書
return_cvbooster=Trueにすると訓練済みブースターも戻す
Scikit-learn API
Feature importance
- Split
- モデルの中で特徴量が使用された回数
- Gain
- その特徴量を使用したsplitによる総gain
Advanced Topics
https://lightgbm.readthedocs.io/en/latest/Advanced-Topics.html#advanced-topics